Implementing your own TF solver
Based on Lecture 4 implement your own TF solver
Hint: See also TF’s repository for additional examples
Import required objecs
import numpy as np
import matplotlib.pyplot as PLT
from matplotlib.ticker import MaxNLocator
import os
import IPython
import tensorflow as tf
import tensorflow_addons as tfa
from tensorflow import keras
import keras.backend as K
from tensorflow.python.ops import array_ops, math_ops, state_ops, control_flow_ops
from tensorflow.keras.models import Sequential
from tensorflow.keras.applications.vgg16 import VGG16
from tensorflow.keras.layers import (
Dense,
Conv2D,
MaxPool2D,
Flatten,
Dropout,
BatchNormalization,
)
from tensorflow.keras.datasets import mnist
from tensorflow.keras.datasets import cifar10
Used to avoid cluttering the output
import tqdm
import tensorflow_addons as tfa
Create a simple TF network
def create_SimpleNet(opName, inShape, nClasses):
model = tf.keras.Sequential([
#
keras.layers.Flatten(),
#
keras.layers.Dense(units=512, activation='relu', input_shape=inShape),
#
keras.layers.Dense(units=nClasses, activation='softmax')
])
model.compile(optimizer=opName,loss='categorical_crossentropy', metrics=['accuracy'],)
return model
Define some utility functions
def stdPreproc(dIn,L=255.0, flagNorm=True, flagMean=True):
dIn = dIn.astype("float")
if flagNorm:
dIn = dIn/L
if flagMean:
mean = np.mean(dIn, axis = 0)
dIn -= mean
return(dIn)
def load_mnist():
(x_train, y_train), (x_valid, y_valid) = mnist.load_data()
return (x_train, y_train), (x_valid, y_valid)
def load_cifar10():
(x_train, y_train), (x_valid, y_valid) = cifar10.load_data()
return (x_train, y_train), (x_valid, y_valid)
Defining a "lr" scheduler
def schedulerBLK20(epoch, lr):
if np.remainder(epoch, 20)!=0 or epoch==0:
return lr
else:
return lr * 0.5
Setting up the network and solvers
def HoSGD_testNetwork(lr, nEpoch, blkSize, num_categories=10, modelFun=create_SimpleNet, mtmVal=0.9, epsAdam=1e-8):
#
# HoSGD_testNetwork(0.001, 50, 128)
#
# ----------
# Read data
# ----------
(x_train, y_train), (x_valid, y_valid) = load_cifar10()
# pre-processing
x_train = stdPreproc(x_train)
x_valid = stdPreproc(x_valid)
# add categories
y_train = keras.utils.to_categorical(y_train, num_categories)
y_valid = keras.utils.to_categorical(y_valid, num_categories)
# ----------
# Optimizers
# ----------
model = []
HName = []
callbackList = []
# SGD
tfOpt = tf.keras.optimizers.SGD(learning_rate=lr,momentum=0.0,nesterov=False)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF SGD - lr {:.3f}'.format(lr))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
# SGD+MTM
tfOpt = tf.keras.optimizers.SGD(learning_rate=lr,momentum=mtmVal,nesterov=False)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF MTM - lr {:.3f}, momentum {:.3f}'.format(lr,mtmVal))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
# Adam
tfOpt = tf.keras.optimizers.Adam(learning_rate=lr,beta_1=0.9, beta_2=0.999, epsilon=epsAdam)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF Adam - lr {:.3f} - $\epsilon$({:.2e})'.format(lr, epsAdam))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
# Adam + sch20
tfOpt = tf.keras.optimizers.Adam(learning_rate=lr,beta_1=0.9, beta_2=0.999, epsilon=epsAdam)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF Adam - lr {:.3f} - $\epsilon$({:.2e}) - sch20'.format(lr, epsAdam))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
callbackList[3].extend( [ tf.keras.callbacks.LearningRateScheduler(schedulerBLK20) ] )
# -------------
# Execute model
# -------------
print('\n')
print('==='*5)
History = {}
for k in range(len(HName)):
K.clear_session()
print('\n')
print('Training: ',HName[k])
strategy = tf.distribute.MultiWorkerMirroredStrategy()
History[HName[k]] = model[k].fit(x_train, y_train, epochs=nEpoch, validation_data=(x_valid, y_valid),
batch_size=blkSize,
verbose=0, callbacks=callbackList[k])
print('\n')
print('==='*5)
print('\n')
#=====================================
# Plot results
plotTFsims(History)
#=====================================
# Clean-up
# For Jupyter
#app = IPython.Application.instance()
#app.kernel.do_shutdown(True)
return History
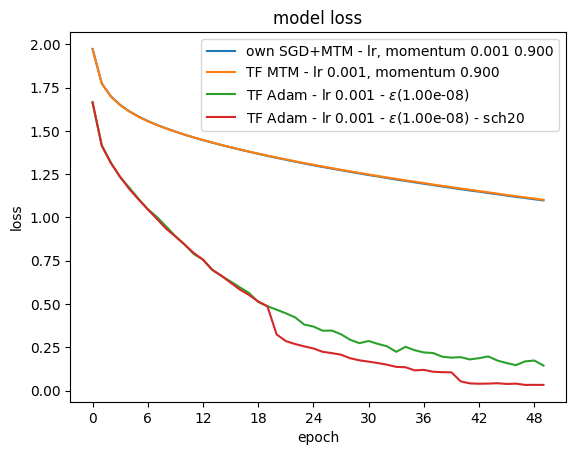
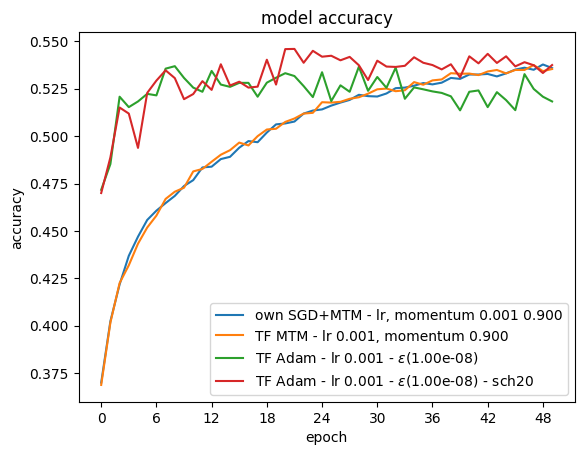
Simple simulation
import HoSGDlabTF as hosgdTF
sol = hosgdTF.HoSGD_TestNetwork(0.001, 50, 128)
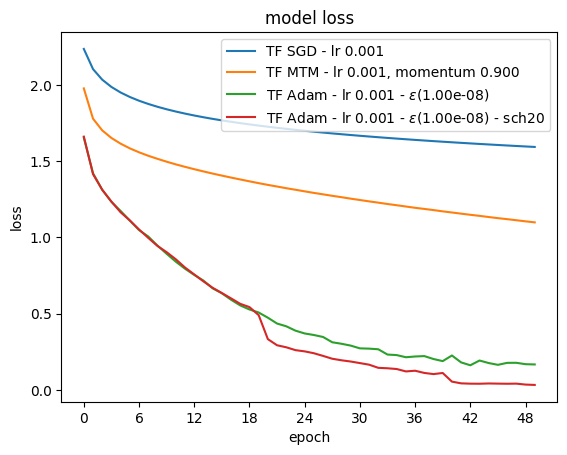
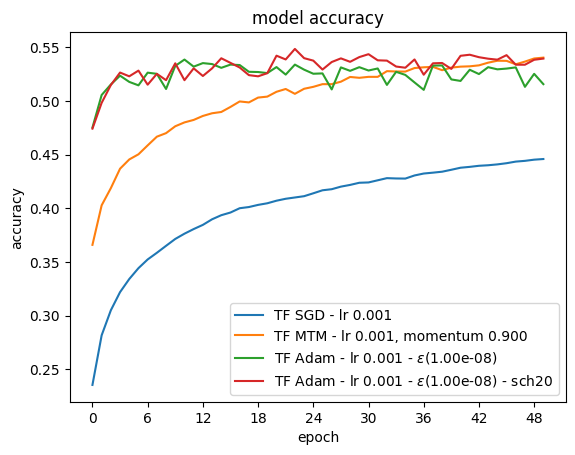
Proposed solution
Among other possible choices, the SGD Momentum variant algorithm is implemented below
Full solution
Own solver ("basic" Momentum)
class HoSGD_sgdM(keras.optimizers.Optimizer):
def __init__(self,learning_rate=0.001, gamma = 0.9,
# --
name="HoSGD_sgdM",
jit_compile=True,
**kwargs):
super().__init__(
name=name,
**kwargs
)
self._learning_rate = self._build_learning_rate(learning_rate)
self.gamma = gamma
def build(self, var_list):
"""Initialize optimizer variables."""
super().build(var_list)
if hasattr(self, "_built") and self._built:
return
self._zVar = []
for var in var_list:
self._zVar.append(
self.add_variable_from_reference(
model_variable=var, variable_name="z"
)
)
self._built = True
def update_step(self, gradient, variable):
"""Update step given gradient and the associated model variable."""
# learning rate
lr = tf.cast(self.learning_rate, variable.dtype)
# iteration
k = tf.cast(self.iterations + 1, variable.dtype)
# Parameters
gamma = tf.cast(self.gamma, variable.dtype)
# -----------------------
# --- Local variables ---
var_key = self._var_key(variable)
# zVar
z = self._zVar[self._index_dict[var_key]]
# -----------------------
if isinstance(gradient, tf.IndexedSlices):
# ----------------
# Sparse gradients
raise NotImplementedError
else:
# ----------------
# Dense gradients
# z = gamma*z - lr*grad
z.assign(gamma*z - lr*gradient)
# u = u + z
variable.assign_add(z)
def get_config(self):
config = super().get_config()
config.update(
{
"learning_rate": self._serialize_hyperparameter(self._learning_rate),
"gamma": self.gamma,
}
)
return config
Setting up the network and solvers
def HoSGD_TestOwnNetwork(lr, nEpoch, blkSize, num_categories=10, modelFun=create_SimpleNet, mtmVal=0.9, epsAdam=1e-8):
#
# HoSGD_testNetwork(0.001, 50, 128)
#
# ----------
# Read data
# ----------
(x_train, y_train), (x_valid, y_valid) = load_cifar10()
# pre-processing
x_train = stdPreproc(x_train)
x_valid = stdPreproc(x_valid)
# add categories
y_train = keras.utils.to_categorical(y_train, num_categories)
y_valid = keras.utils.to_categorical(y_valid, num_categories)
# ----------
# Optimizers
# ----------
model = []
HName = []
callbackList = []
# SGD+MTM own
ownOpt = HoSGD_sgdM(learning_rate=lr, gamma=mtmVal)
model.append( modelFun(ownOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('own SGD+MTM - lr, momentum {:.3f} {:.3f}'.format(lr,mtmVal))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
# SGD+MTM
tfOpt = tf.keras.optimizers.SGD(learning_rate=lr,momentum=mtmVal,nesterov=False)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF MTM - lr {:.3f}, momentum {:.3f}'.format(lr,mtmVal))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
# Adam
tfOpt = tf.keras.optimizers.Adam(learning_rate=lr,beta_1=0.9, beta_2=0.999, epsilon=epsAdam)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF Adam - lr {:.3f} - $\epsilon$({:.2e})'.format(lr, epsAdam))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
# Adam + sch20
tfOpt = tf.keras.optimizers.Adam(learning_rate=lr,beta_1=0.9, beta_2=0.999, epsilon=epsAdam)
model.append( modelFun(tfOpt, inShape=[x_train.size], nClasses=num_categories ) )
HName.append('TF Adam - lr {:.3f} - $\epsilon$({:.2e}) - sch20'.format(lr, epsAdam))
callbackList.append( [tfa.callbacks.TQDMProgressBar(leave_epoch_progress=True,show_epoch_progress=False)] )
callbackList[3].extend( [ tf.keras.callbacks.LearningRateScheduler(schedulerBLK20) ] )
# -------------
# Execute model
# -------------
print('\n')
print('==='*5)
History = {}
for k in range(len(HName)):
K.clear_session()
print('\n')
print('Training: ',HName[k])
strategy = tf.distribute.MultiWorkerMirroredStrategy()
History[HName[k]] = model[k].fit(x_train, y_train, epochs=nEpoch, validation_data=(x_valid, y_valid),
batch_size=blkSize,
verbose=0, callbacks=callbackList[k])
print('\n')
print('==='*5)
print('\n')
#=====================================
# Plot results
plotTFsims(History)
return History
Simple simulation
import HoSGDlabOwnTF as hosgdOTF
sol = hosgdOTF.HoSGD_TestOwnNetwork(0.001, 50, 128)