GD
Consider cost functional
\(\nabla F\) is \(L\)-Lipschitz continuous: \(\| \nabla F(\mathbf{x}) - \nabla F(\mathbf{y}) \|_2 \leq L(F)\| \mathbf{x} - \mathbf{y} \|_2\),
\(\mathbf{u} \in \mathbb{R}^{n_1 \times n_2 \times \ldots}\),
\(\mbox{Op}(\cdot) : \mathbb{R}^{n_1 \times n_2 \times \ldots} \mapsto \mathbb{R}^L\) represents a forward operator,
\(\mathbf{b} \in \mathbb{R}^L\) represents some vectorized observed/input data.
\(f(\cdot) : \mathbb{R}^L \mapsto \mathbb{R}\) is a loss (cost) function.
Quadratic cost along with a linear operator
\[\begin{eqnarray*} F(\mathbf{u}) = 0.5 \| A\mathbf{u} - \mathbf{b} \|_2^2\end{eqnarray*}\]
Problem: write you own GD routine; as a test function use a quadratic loss (such the one considered in the “simple example” tab of the above panel).
Proposed solution
Among other pausible alternatives, the GD algorithm may be written as
def hosgdGD(OptProb, nIter, alpha0, hyperFun):
u = OptProb.randSol()
stats = np.zeros( [nIter, OptProb.Nstats] )
for k in range(nIter):
g = OptProb.gradFun(u)
alpha = hyperFun.SS(u, alpha0, k, g)
u = u - alpha*g
stats[k,:] = OptProb.computeStats(u, alpha, k, g)
OptProb.printStats(k, nIter, stats)
return u, stats
def hosgdGD(OptProb, nIter, alpha0, hyperFun):
OptProb
classthat encapsultes a particular optimization problem.Given the function \(F(\cdot) : \mathbb{R}^N \mapsto \mathbb{R}\), this
classshould implementcostFun: computes the cost functional.gradFun: computes the gradient, i.e. \( \nabla F(\cdot) \).randSol: generates a random initial solutionfwOp: operator (function) that maps or transforms variable \(\mathbf{u} \in \mathbf{R}^{n_1 \times n_2 \times \ldots}\) into \(\mathbf{R}^N\), e.g. \(A \mathbf{u} \), where \(A \in \mathbf{R}^{N \times M}\), and \(\mathbf{u} \in \mathbf{R}^{M} \).computeStats: gathers useful statistics (e.g. cost functional, current step-size value, etc.).
class hosgdFunQlin(hosgdOptProb):
r""" 0.5|| Au - b ||_2^2
"""
def __init__(self, A, b, Nstats=3, verbose=10, initSol=None):
self.A = A
self.b = b
self.Nstats = Nstats
self.verbose = verbose
self.initSol = initSol # if not None --> reproducible initial solution
# ---------
# ---------
def costFun(self, u):
return 0.5*np.linalg.norm( self.A.dot(u).ravel()-self.b.ravel(), ord=2)**2
# ---------
def fwOp(self, u):
return self.A.dot(u)
# ---------
def gradFun(self, u):
return self.A.transpose().dot(self.A.dot(u) - self.b)
# ---------
def randSol(self):
if self.initSol is None:
rng = np.random.default_rng()
else:
rng = np.random.default_rng(self.initSol)
return rng.normal(size=[self.A.shape[1],1])
# ---------
def computeStats(self, u, alpha, k, g):
cost = self.costFun(u)
return np.array([k, cost, alpha])
def printStats(self, k, nIter, v):
if k == 0:
print('\n')
if self.verbose > 0:
if np.remainder(k,self.verbose)==0 or k==nIter-1:
print('{:>3d}\t {:.3e}\t {:.2e} '.format(int(v[k,0]),v[k,1],v[k,2]))
return
nIter
alpha0
hyperFun
classthat encapsultes any functionality related to GD’s hyper-parameters.Up to this point, this
classwould only focus on computing the step-size \(\alpha\).
class hosgdHyperFun(object):
r"""Class related to routines associated to hyperPars computation
"""
def __init__(self, OptProb, ssPolicy=hosgdDef.ss.Cte):
self.ssPolicy = ssPolicy
self.fwOp = OptProb.fwOp
self.SS = self.sel_SS()
def sel_SS(self):
switcher = {
hosgdDef.ss.Cte.val: self.ssCte,
hosgdDef.ss.Cauchy.val: self.ssCauchy,
hosgdDef.ss.CauchyLagged.val: self.ssCauchyLagged,
hosgdDef.ss.BBv1.val: self.ssBBv1,
hosgdDef.ss.BBv2.val: self.ssBBv2,
hosgdDef.ss.BBv3.val: self.ssBBv3,
}
ssFun = switcher.get(self.ssPolicy.val, "nothing")
func = lambda u, alpha, k, g: ssFun(u, alpha, k, g)
return func
# --- === ---
def ssCte(self, u, alpha, k, g):
return alpha
# --- Routines below will be implement later.
def ssCauchy(self, u, alpha, k, g):
pass
def ssCauchyLagged(self, u, alpha, k, g):
pass
def ssBBv1(self, u, alpha, k, g):
pass
def ssBBv2(self, u, alpha, k, g):
pass
def ssBBv3(self, u, alpha, k, g):
pass
from enum import Enum, IntEnum, unique
@unique
class ss(Enum):
Cte = (0, 'Cte step-size')
Cauchy = (1, 'Cauchy')
CauchyLagged = (2, 'Cauchy-BB (lagged)')
BBv1 = (6, 'BBv1')
BBv2 = (7, 'BBv2')
BBv3 = (8, 'BBv3')
def __init__(self, val, txt):
self.val = val
self.txt = txt
@classmethod
def printSS(cls):
for k in cls:
print('ss.{}:'.format(k.name), k.val, k.txt)
Simulation
1. Generate input data
import numpy as np
# --- Data generation (N,M: user inputs)
# --------------------------------------
rng = np.random.default_rng()
A = rng.normal(size=[N,M])
D = np.sqrt(max(N,M))*np.diag( rng.random([max(N,M),]), 0)
A += D[0:N,0:M]
A /= np.linalg.norm(A,axis=0)
xOrig = np.random.randn(M,1)
b = A.dot(xOrig) + sigma*np.random.randn(N,1)
2. Load the optimization problem
# --- Optimization model
# --- (see "Parameters", "OptProb", "E.g. quadratic func."
# in the tabbed panel above)
# ---------------------------------------------------------
OptProb = hosgdFunQlin(A,b)
3. Select the hyper-parameters routines
# --- It is assumed that class 'ss' is defined
# in file 'HoSGDdefs.py'
# --- (see "Parameters", "hyperFun", "class ss"
# in the tabbed panel above)
# ---------------------------------------------------------
import HoSGDdefs as hosgdDef
# --- hyperPars
# --- (see "Parameters", "hyperFun", "E.g."
# in the tabbed panel above)
# ---------------------------------------------------------
hyperP = hosgdHyperFun(OptProb, ssPolicy=hosgdDef.ss.Cte)
4. Execute GD
# --- nIter, alpha0: user defined.
# --- OptProb: see #2 in the current list
# --- hyperP: see #3 in the current list
u, stats = hosgdGD(OptProb, nIter, alpha0, hyperP)
Full solution
HoSGDdefs.py
from enum import Enum, IntEnum, unique
from enum import Enum, IntEnum, unique
@unique
class ss(Enum):
Cte = (0, 'Cte step-size')
def __init__(self, val, txt):
self.val = val
self.txt = txt
@classmethod
def printSS(cls):
for k in cls:
print('ss.{}:'.format(k.name), k.val, k.txt)
ReLU = (0, 'ReLU')
RReLU = (1, 'Rand ReLU')
ELU = (2, 'ELU')
def __init__(self, val, txt):
self.val = val
self.txt = txt
@classmethod
def printLR(cls):
for k in cls:
print('actFun.{}:'.format(k.name), k.val, k.txt)
@unique
class hlFun(Enum):
dense = (0, 'Dense (matrix times)')
def __init__(self, val, txt):
self.val = val
self.txt = txt
class `OptProb` (bare-bones)
class hosgdOptProb(object):
r"""Simple class to describe the attributtes of an optimization problem
"""
def __init__(self):
pass
def costFun(self, u):
pass
def gradFun(self, u):
pass
def randSol(self):
return None
def gradNorm(self, g, ord=2):
return None
HoSGDL1a.py
import numpy as np
import scipy as sc
from scipy import signal
import matplotlib.pylab as PLT
import HoSGDdefs as hosgdDef
from HoSGDdefs import hosgdOptProb
class hosgdHyperFun(object):
r"""Class related to routines associated to hyperPars computation
"""
def __init__(self, OptProb, ssPolicy=hosgdDef.ss.Cte):
self.ssPolicy = ssPolicy
self.fwOp = OptProb.fwOp
self.SS = self.sel_SS()
def sel_SS(self):
switcher = {
hosgdDef.ss.Cte.val: self.ssCte,
hosgdDef.ss.Cauchy.val: self.ssCauchy,
hosgdDef.ss.CauchyLagged.val: self.ssCauchyLagged,
hosgdDef.ss.BBv1.val: self.ssBBv1,
hosgdDef.ss.BBv2.val: self.ssBBv2,
hosgdDef.ss.BBv3.val: self.ssBBv3,
}
ssFun = switcher.get(self.ssPolicy.val, "nothing")
func = lambda u, alpha, k, g: ssFun(u, alpha, k, g)
return func
# --- === ---
def ssCte(self, u, alpha, k, g):
return alpha
class hosgdFunQlin(hosgdOptProb):
r""" 0.5|| Au - b ||_2^2
"""
def __init__(self, A, b, gNormOrd=2, Nstats=4, verbose=10, initSol=None):
self.A = A
self.b = b
self.gNormOrd = gNormOrd
self.Nstats = Nstats
self.verbose = verbose
self.initSol = initSol # if not None --> reproducible initial solution
# ---------
# ---------
def costFun(self, u):
return 0.5*np.linalg.norm( self.A.dot(u).ravel()-self.b.ravel(), ord=2)**2
# ---------
def fwOp(self, u):
return self.A.dot(u)
# ---------
def gradFun(self, u):
return self.A.transpose().dot(self.A.dot(u) - self.b)
# ---------
def randSol(self):
if self.initSol is None:
rng = np.random.default_rng()
else:
rng = np.random.default_rng(self.initSol)
return rng.normal(size=[self.A.shape[1],1])
# ---------
def computeStats(self, u, alpha, k, g):
cost = self.costFun(u)
gNorm = self.gradNorm(g, self.gNormOrd)
return np.array([k, cost, alpha, gNorm])
def printStats(self, k, nIter, v):
if k == 0:
print('\n')
if self.verbose > 0:
if np.remainder(k,self.verbose)==0 or k==nIter-1:
print('{:>3d}\t {:.3e}\t {:.2e} {:.2e}'.format(int(v[k,0]),v[k,1],v[k,2],v[k,3]))
return
def gradNorm(self, g, ord=2):
if g is None:
return -1.0
if ord == 2:
return np.linalg.norm(g.ravel(),ord=ord)**ord
else:
return np.linalg.norm(g.ravel(),ord=ord)
# ===========================================
def hosgdGD(OptProb, nIter, alpha0, hyperFun):
u = OptProb.randSol()
stats = np.zeros( [nIter, OptProb.Nstats] )
for k in range(nIter):
g = OptProb.gradFun(u)
alpha = hyperFun.SS(u, alpha0, k, g)
u = u - alpha*g
stats[k,:] = OptProb.computeStats(u, alpha, k, g)
OptProb.printStats(k, nIter, stats)
return u, stats
def exQlin(nIter, alpha, N=1000, M=500, sigma=0.05, ssPolicy=hosgdDef.ss.Cte):
# Examples
# u, st = H.exQlin(40, np.array([0.05, 0.01, 0.001]), N=500, M=2000, ssPolicy=H.hosgdDef.ss.Cte)
# --- Data generation
# -------------------
rng = np.random.default_rng()
A = rng.normal(size=[N,M])
D = np.sqrt(max(N,M))*np.diag( rng.random([max(N,M),]), 0)
A += D[0:N,0:M]
A /= np.linalg.norm(A,axis=0)
xOrig = np.random.randn(M,1)
b = A.dot(xOrig) + sigma*np.random.randn(N,1)
# --- Optimization model
# ----------------------
OptProb = hosgdFunQlin(A,b)
# --- HyperPar
# ------------
if isinstance(ssPolicy, list):
u = []
stats = []
ssPlcyList = []
alphaList = []
for n in range(len(ssPolicy)):
hyperP = hosgdHyperFun(OptProb, ssPolicy=ssPolicy[n])
sol = hosgdGD(OptProb, nIter, alpha, hyperP)
u.append(sol[0])
stats.append(sol[1])
ssPlcyList.append( ssPolicy[n] )
alphaList.append(alpha)
stDict = {'stats': stats, 'ssPlcy': ssPlcyList, 'alphaVal': alphaList, 'alphaPlot':True}
plotGDDictStats(stDict)
else:
hyperP = hosgdHyperFun(OptProb, ssPolicy=ssPolicy)
# --- Call GD
# -----------
u, stats = runGD(OptProb, nIter, alpha, hyperP, ssPolicy)
return u, stats
def runGD(OptProb, nIter, alpha, hyperP, ssPolicy):
if hasattr(alpha, "shape"):
u = []
stats = []
ssPlcyList = []
for n in range(alpha.shape[0]):
sol = hosgdGD(OptProb, nIter, alpha[n], hyperP)
u.append(sol[0])
stats.append(sol[1])
if isinstance(ssPolicy, list):
ssPlcyList.append( ssPolicy[n] )
flagAlphaPlot = True
else:
ssPlcyList.append( ssPolicy )
flagAlphaPlot = False
stDict = {'stats': stats, 'ssPlcy': ssPlcyList, 'alphaVal': alpha, 'alphaPlot':flagAlphaPlot}
plotGDDictStats(stDict)
else:
u, stats = hosgdGD(OptProb, nIter, alpha, hyperP)
plotGDStats(stats, ssPolicy)
return u, stats
def plotGDStats(stats, ssPolicy):
# --- Plot results ---
PLT.figure()
PLT.plot(stats[:,1], label=r'$\alpha_k$ : {0}'.format(ssPolicy.txt) )
PLT.legend(loc='upper right')
PLT.ylabel(r'$f(x) = \frac{1}{2}\| A \mathbf{x} - \mathbf{b} \|_2^2$', fontsize=16)
PLT.xlabel('Iteration', fontsize=16)
if ssPolicy.val > 0:
PLT.figure()
PLT.plot(stats[1::,2], label=r'$\alpha_k$ : {0}'.format(ssPolicy.txt) )
PLT.legend(loc='upper right')
PLT.ylabel(r'$\alpha$', fontsize=20)
PLT.xlabel('Iteration', fontsize=16)
PLT.show()
def plotGDDictStats(stDict):
stats = stDict.get('stats')
ssPlcy = stDict.get('ssPlcy')
alpha = stDict.get('alphaVal')
alphaPlot = stDict.get('alphaPlot')
# --- Plot cost function ---
PLT.figure()
for n in range(len(stats)):
PLT.semilogy(stats[n][:,1], label=r'$\alpha_k$ : {0} -- {1}'.format(alpha[n], ssPlcy[n].txt) )
PLT.legend(loc='upper right')
PLT.ylabel(r'$f(x) = \frac{1}{2}\| A \mathbf{x} - \mathbf{b} \|_2^2$', fontsize=16)
PLT.xlabel('Iteration', fontsize=16)
PLT.title('Cost functional',fontsize=16)
# --- Plot SS ---
if alphaPlot:
PLT.figure()
for n in range(len(stats)):
PLT.plot(stats[n][1::,2], label=r'$\alpha_k$ : {0}'.format(ssPlcy[n].txt) )
PLT.legend(loc='upper right')
PLT.ylabel(r'$\alpha$', fontsize=20)
PLT.xlabel('Iteration', fontsize=16)
PLT.title('Step-size',fontsize=16)
# ---
# --- Plot gradNorm ---
if False:
PLT.figure()
for n in range(len(stats)):
PLT.semilogy(stats[n][1::,3], label=r'$\alpha_k$ : {0}'.format(ssPlcy[n].txt) )
PLT.legend(loc='upper right')
PLT.ylabel(r'$\| \nabla F \|_2$', fontsize=20)
PLT.xlabel('Iteration', fontsize=16)
PLT.title('Gradient norm',fontsize=16)
# ---
PLT.show()
Simple Simulation
import numpy as np
import HoSGDlabGD as H
# run simple example
u, st = H.exQlin(40, 0.01, N=500, M=2000)
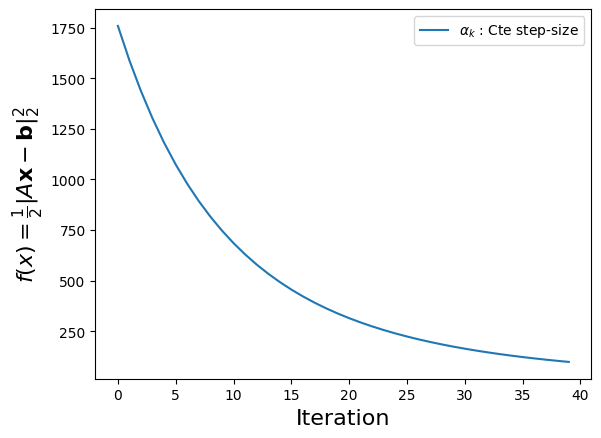
Using several step-sizes
alpha = np.array([0.05, 0.01, 0.001])
# run example with several ss
u, st = H.exQlin(40, alpha, N=500, M=2000)
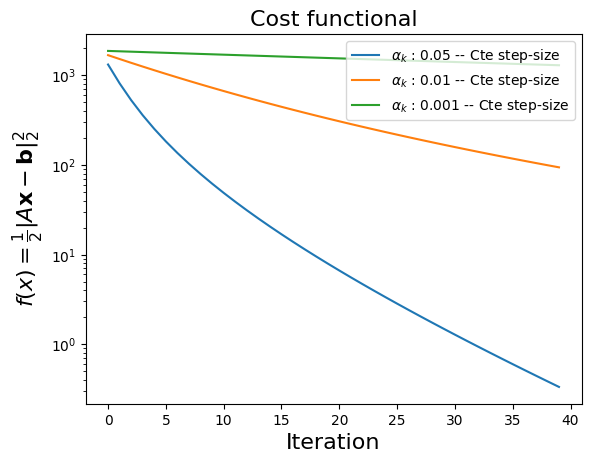
Running the simulations within Colab
Sign-in into Colab
Upload the necessary files; for this example:
HoSGDlabGD.py
HoSGDdefs.py
In Colab, execute
from google.colab import files
src = list(files.upload().values())[0]
Proceed as shown above