Backpropagation
Considering a cost functional with the same characteristics as the one used for the SGD case, then
Modify the SGD routine so as to integrate it along with the backpropagation algorithm
Test such modification on the classification problem solved by an architecture that includes one hidden layer
As detailed in the ELM simulation the Softmax function along with a hidden layer can be summarized by
where
\(\mathbf{Z}_0 = \mathbf{X} \in \mathbb{R}^{r_0 \times N}\) represents the input dataset which has \(L\) classes.
\(\mathbf{Z}_1 = \varphi_1(\mathbf{W_0}\mathbf{Z}_0) \in \mathbb{R}^{r_1 \times N}\) represents a dense hidden layer.
\(\mathbf{W}_0 \in \mathbb{R}^{r_1 \times r_0}\): hidden layer’s weights.
\(\varphi_1(\cdot)\) is a non-linear activation function.
\(\mathbf{W}_1 \in \mathbb{R}^{r_1 \times L}\): softmax’s layer weights.
Typical case \(r_1 \ll r_0 \) (at least \(r_1 < r_0 \)).
and the vectors
\(\mathbf{c}_n^{^{(\mathbf{z})}}\) represents a canonical vector of length \(\mathbf{Z}.\mbox{shape}[1]\)
\(\mathbf{c}_l\) represents a canonical vector of length L
\(\mathbf{h}_n \in \mathbb{R}^L\) is the one-hot representation of \(n^{th}\) training element’s class.
are used to extract a particular column of a given matrix.
Using this notation, then the backpropagation algorithm applied to this case (for a full explanation see Lecture 3b’s Introduction & BP: softmax+HL sections) may be summarized by
where (2.1)-(2.3) are part of the forward pass, and (2.4) is the backward pass; furthermore, it is relevant to highlight that
\(\mathbf{H} \in \mathbb{R}^{L \times N}\) represents the one-hot matrix associated with the training dataset.
\(\mbox{softmax}(\mathbf{V}, \mbox{axis=1}) = \mathbf{S}\), where:
\(\mathbf{V}, \mathbf{S} \in \mathbb{R}^{\kappa \times \eta}\)
\(\mathbf{S}[k,:] = \frac{\mbox{e}^{\mathbf{V}[k,:]}}{\sum_{n=1}^\eta \mbox{e}^{\mathbf{V}[k,n]} }\)
Proposed solution
Among other pausible solutions, the proposed one is detailed below
Differences between SGD and SGD+BP
Each of the tabs below highlights the key difference between the original SGD routine and the one that includes the backpropagation and trains a hidden layer.
SGD SGD+BP def hosgdSGD(OptProb, nEpoch, blkSize, alpha0, hyperFun): W = OptProb.randSol() stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize # Compute the gradient g = OptProb.gradFun(W, n) alpha = hyperFun.LR(W, alpha0, e, None) W = W - alpha*g # _END_ for(b) stats[e,:] = OptProb.computeStats(W, alpha, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
def hosgdSGDHLSover(OptProb, sgdVariant, nEpoch, blkSize): W = [] OptProb.setShapes() for l in range(len(OptProb.HL)): W.append( OptProb.HL[l].randSol( OptProb.zShape[l] ) ) stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 # pass OptProb's basic info to sgdVariant sgdVariant.getArchConf( OptProb.HL ) k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize x = OptProb.X[:,np.ix_(n)].squeeze(1).copy() y = OptProb.Y[n] # -- fw operator, i.e: z_l = \phi_l( W[l-1], z[l-1]) -- OptProb.fwOperator(W, x, y) # Compute the gradient -- (FwPass, bwPass) -- for l in range(len(OptProb.HL)-1,-1,-1): # fw Pass OptProb.fwPass(W, y, l) # bw Pass g = OptProb.bwPass(W, y, l) # Update gradient W[l] = sgdVariant.update( W[l].copy(), g, e, l) stats[e,:] = OptProb.computeStats(W, sgdVariant.alpha0, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
SGD SGD+BP def hosgdSGD(OptProb, nEpoch, blkSize, alpha0, hyperFun): W = OptProb.randSol() stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize # Compute the gradient g = OptProb.gradFun(W, n) alpha = hyperFun.LR(W, alpha0, e, None) W = W - alpha*g # _END_ for(b) stats[e,:] = OptProb.computeStats(W, alpha, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
def hosgdSGDHLSover(OptProb, sgdVariant, nEpoch, blkSize): W = [] OptProb.setShapes() for l in range(len(OptProb.HL)): W.append( OptProb.HL[l].randSol( OptProb.zShape[l] ) ) stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 # pass OptProb's basic info to sgdVariant sgdVariant.getArchConf( OptProb.HL ) k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize x = OptProb.X[:,np.ix_(n)].squeeze(1).copy() y = OptProb.Y[n] # -- fw operator, i.e: z_l = \phi_l( W[l-1], z[l-1]) -- OptProb.fwOperator(W, x, y) # Compute the gradient -- (FwPass, bwPass) -- for l in range(len(OptProb.HL)-1,-1,-1): # fw Pass OptProb.fwPass(W, y, l) # bw Pass g = OptProb.bwPass(W, y, l) # Update gradient W[l] = sgdVariant.update( W[l].copy(), g, e, l) stats[e,:] = OptProb.computeStats(W, sgdVariant.alpha0, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
SGD SGD+BP def hosgdSGD(OptProb, nEpoch, blkSize, alpha0, hyperFun): W = OptProb.randSol() stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize # Compute the gradient g = OptProb.gradFun(W, n) alpha = hyperFun.LR(W, alpha0, e, None) W = W - alpha*g # _END_ for(b) stats[e,:] = OptProb.computeStats(W, alpha, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
def hosgdSGDHLSover(OptProb, sgdVariant, nEpoch, blkSize): W = [] OptProb.setShapes() for l in range(len(OptProb.HL)): W.append( OptProb.HL[l].randSol( OptProb.zShape[l] ) ) stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 # pass OptProb's basic info to sgdVariant sgdVariant.getArchConf( OptProb.HL ) k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize x = OptProb.X[:,np.ix_(n)].squeeze(1).copy() y = OptProb.Y[n] # -- fw operator, i.e: z_l = \phi_l( W[l-1], z[l-1]) -- OptProb.fwOperator(W, x, y) # Compute the gradient -- (FwPass, bwPass) -- for l in range(len(OptProb.HL)-1,-1,-1): # fw Pass OptProb.fwPass(W, y, l) # bw Pass g = OptProb.bwPass(W, y, l) # Update gradient W[l] = sgdVariant.update( W[l].copy(), g, e, l) stats[e,:] = OptProb.computeStats(W, sgdVariant.alpha0, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
SGD SGD+BP def hosgdSGD(OptProb, nEpoch, blkSize, alpha0, hyperFun): W = OptProb.randSol() stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize # Compute the gradient g = OptProb.gradFun(W, n) alpha = hyperFun.LR(W, alpha0, e, None) W = W - alpha*g # _END_ for(b) stats[e,:] = OptProb.computeStats(W, alpha, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
def hosgdSGDHLSover(OptProb, sgdVariant, nEpoch, blkSize): W = [] OptProb.setShapes() for l in range(len(OptProb.HL)): W.append( OptProb.HL[l].randSol( OptProb.zShape[l] ) ) stats = np.zeros( [nEpoch, OptProb.Nstats] ) nBlk = np.floor_divide(OptProb.X.shape[1],blkSize) if np.remainder(OptProb.X.shape[1],blkSize) > 0: nBlk += 1 # pass OptProb's basic info to sgdVariant sgdVariant.getArchConf( OptProb.HL ) k = 0 for e in range(nEpoch): # Generate permutation blkInd = 0 perm = np.random.permutation(OptProb.X.shape[1]) for b in range(nBlk): # general iteration counter k += 1 # select indexes if b <= nBlk-2: n = perm[blkInd:blkInd+blkSize] else: n = perm[blkInd:OptProb.X.shape[1]] blkInd += blkSize x = OptProb.X[:,np.ix_(n)].squeeze(1).copy() y = OptProb.Y[n] # -- fw operator, i.e: z_l = \phi_l( W[l-1], z[l-1]) -- OptProb.fwOperator(W, x, y) # Compute the gradient -- (FwPass, bwPass) -- for l in range(len(OptProb.HL)-1,-1,-1): # fw Pass OptProb.fwPass(W, y, l) # bw Pass g = OptProb.bwPass(W, y, l) # Update gradient W[l] = sgdVariant.update( W[l].copy(), g, e, l) stats[e,:] = OptProb.computeStats(W, sgdVariant.alpha0, e, g) OptProb.printStats(e, nEpoch, stats) return W, stats
New structure for the OptProb class
class hosgdHLOptProb(hosgdOptProb): r""" F(W) = (1/N) \sum_n f_n(W) f_n(W) = < Xn, Wl_n > + log( \sum_l e^{ -< Xl, Wl >} ) """ def __init__(self, X, Y, nClass, HL, Xtest=None, Ytest=None, lmbd=0, gNormOrd=2, Nstats=4, verbose=10): self.X = X self.Y = Y self.nClass = nClass self.Xtest = Xtest self.Ytest = Ytest self.lmbd = lmbd self.Nstats = Nstats self.gNormOrd = gNormOrd self.verbose = verbose self.HL = HL self.fwOpFlag = False self.fwPassFlag = False # --------- def setShapes(self): self.zShape = np.zeros( len(self.HL), dtype=int ) # input layer self.zShape[0] = self.X.shape[0] # for l in range( 1, len(self.HL) ): self.zShape[l] = self.HL[l-1].nShp # --------- def fwOperator(self, W, x, y): if self.fwOpFlag: #self.z[0] = self.HL[0].fwd(W[0], x) self.z[0] = x for l in range( 1, len(self.HL) ): self.z[l] = self.HL[l-1].fwd( W[l-1], self.z[l-1] ) else: #first call self.z = [] self.z.append( x ) for l in range( 1, len(self.HL) ): self.z.append( self.HL[l-1].fwd(W[l-1], self.z[l-1] ) ) self.fwOpFlag = True # --------- def fwPass(self, W, y, l): if self.fwPassFlag: if l == len(self.HL)-1: self.grad[l] = self.HL[l].gradFun( W[l], self.z[l], y) else: self.nabZ[l+1] = self.HL[l+1].gradFunZVar(W[l+1], self.z[l+1], y) self.nabW[l] = self.HL[l].gradFunWVar( W[l], self.z[l], y) else: #first call if l == len(self.HL)-1: self.grad = [None]*len(self.HL) self.nabZ = [None]*len(self.HL) self.nabW = [None]*len(self.HL) self.grad[l] = self.HL[l].gradFun( W[l], self.z[l], y) else: self.nabZ[l+1] = self.HL[l+1].gradFunZVar(W[l+1], self.z[l+1], y) self.nabW[l] = self.HL[l].gradFunwVar( W[l], self.z[l], y) self.fwPassFlag = True # --------- def bwPass(self, W, y, l): if l == len(self.HL)-1: pass # do nothing since the 1st level (output's perspetive) gradient # is already computed else: self.grad[l] = self.HL[l].gradFun(self.nabW[l], self.nabZ[l+1], self.z[l]) return self.grad[l] # --------- def computeStats(self, W, alpha, k, g): cost = self.costFun(W) success = self.computeSuccess(W) return np.array([k, cost, alpha, success]) # --------- def costFun(self, W): for l in range( len(self.HL) ): if l == 0: Z = self.HL[l].fwd(W[l], self.X) else: Z = self.HL[l].fwd(W[l], Z) fCost = self.HL[-1].costFun(W[-1], Z, self.Y) return(fCost) def computeSuccess(self, W): if self.Xtest is not None and self.Ytest is not None: for l in range( len(self.HL) ): if l == 0: Z = self.HL[l].fwd(W[l], self.Xtest) else: Z = self.HL[l].fwd(W[l], Z) success = self.HL[-1].computeSuccess(W[-1], Z, self.Ytest) return( success ) else: return None # --------- def printStats(self, k, nEpoch, v): if k == 0: print('\n') if self.verbose > 0: if np.remainder(k,self.verbose)==0 or k==nEpoch-1: if v[k,3] is None: print('{:>3d}\t {:.3e}\t {:.2e}'.format(int(v[k,0]),v[k,1],v[k,2])) else: print('{:>3d}\t {:.3e}\t {:.2e}\n \t \ success rate (training): {:.3e}'.format(int(v[k,0]),v[k,1],v[k,2],v[k,3])) return # --------- def gradNorm(self, g, ord=2): pass
Layers (Softmax and dense) routines that are BP compatible
class hosgdHLFunSoftMax(object): def __init__(self, nShp, lmbd=0, initSol=None): self.nShp = nShp self.lmbd = lmbd self.initSol = initSol # if not None --> reproducible initial solution # --------- def gradFun(self, W, z, y): ##z = self.X[:,np.ix_(n)].squeeze(1) # select batch elements g = -z.dot( softmax(-z.transpose().dot(W),axis=1) ) for k in range(z.shape[1]): g[:,y[k] ] += z[:,k] g /= float(g.shape[1]) if self.lmbd > 0: g += self.lmbd*W return g # --------- def gradFunZVar(self, W, z, y): ## see notes: WH - (1/s)*WE, E = exp(-W^T Z), s = sum(E, axis=0) #g = softmax(-z.transpose().dot(W),axis=1).dot( W.transpose() ).transpose() g = -W.dot( softmax(-z.transpose().dot(W),axis=1).transpose() ) # (1/s)*WE for k in range(z.shape[1]): # g += WH g[:, k ] += W[:, y[k] ] return g # --------- def costFun(self, W, Z, Y): fCost = np.sum(np.log(np.sum(np.exp(Z.transpose().dot(W)), axis=1))) fCost += np.sum( Z*W[:,Y] ) fCost /= float(Z.shape[1]) if self.lmbd > 0: fCost += self.lmbd*(sum( np.power(W.ravel(),2) ))/float(Z.shape[1]) return fCost # --------- def randSol(self, zShape): if self.initSol is None: rng = np.random.default_rng() else: rng = np.random.default_rng(self.initSol) return 0.01*rng.normal(size=[zShape, self.nShp] ) # --------- def fwd(self, A, z, flag=True): return( z ) # --------- def computeSuccess(self, W, Xtest, Ytest): classVal = -np.matmul(Xtest.transpose(), W) success = sum( np.argmax(classVal,axis=1) == Ytest ) return float(success)/float(Xtest.shape[1])
class hosgdHLFunDense(object): def __init__(self, nShp, hlFun=hosgdDef.hlFun.dense, actFun=None, par1=None, par2=None, initSol=None): self.nShp = nShp self.initSol = initSol # if not None --> reproducible initial solution self.par1 = par1 self.par2 = par2 self.hlFun = hlFun self.AFclass = hosgdFunAF(actFun=actFun, par1=par1, par2=par2) self.actFun = self.AFclass.sel_AF() # --------- def gradFunWVar(self, W, z, y): # Note: nabla actFun( W.dot(z) ) = actFun( W.dot(z), True ).dot( z.transpose() ), # nonetheless, since z is accessible, here only actFun( W.dot(z), True ) is returned return self.actFun( W.dot(z), True ) # --------- def gradFunZVar(self, W, z, y): return 1. # --------- def gradFun(self, nabW, nabZ, z): return (nabW*nabZ).dot( z.transpose() ) # --------- def costFun(self, W, Z, Y): pass # --------- def fwd(self, A, z, flag=True): if flag: return( self.actFun( A.dot(z), False ) ) else: return( z ) # --------- def randSol(self, zShape): if self.initSol is None: rng = np.random.default_rng() else: rng = np.random.default_rng(self.initSol) return 0.01*rng.normal(size=[self.nShp, zShape] )
Full solution
Routines to execute example and plot results
def exHLMultiClass(nEpoch, blkSize, alpha, dataset='mnist', actFun=hosgdDef.actFun.ReLU, lrPolicy=hosgdDef.lrSGD.Cte, lrSDecay=20, lrTau = 0.5, verbose=5):
# Examples
# HL.exHLMultiClass(20, 128, np.array([0.001,0.00025]), dataset='cifar10', verbose=10, actFun=hosgdDef.actFun.ReLU)
# sol = HL.exHLMultiClass(50, 128, np.array([0.001,0.00025]), dataset='cifar10', verbose=10,
# actFun=hosgdDef.actFun.ReLU, lrPolicy=hosgdDef.lrSGD.StepDecay, lrSDecay=10, lrTau=0.5)
# w, stats = H.exMultiClass(25, 64, 0.02, dataset='cifar10', lrPolicy=hosgdDef.lrSGD.StepDecay, lrSDecay=10, lrTau=0.5)
# --- Load data
# -------------------
flagDataset = False
if dataset.lower() == 'mnist':
(X, Y), (Xtest, Ytest) = mnist.load_data()
flagDataset = True
if dataset.lower() == 'cifar10':
(X, Y), (Xtest, Ytest) = cifar10.load_data()
flagDataset = True
if flagDataset is False:
print('Dataset {} is no valid'.format(dataset))
return
if verbose == 1:
print('Shape (training data):', X.shape)
print('Shape (valid/testing data):', Xtest.shape)
print('\n')
# pre-processing
X = stdPreproc(X)
Xtest = stdPreproc(Xtest)
# Data vectorization
X = np.transpose( X.reshape(X.shape[0], np.array(X.shape[1::]).prod()) )
Xtest = np.transpose( Xtest.reshape(Xtest.shape[0], np.array(Xtest.shape[1::]).prod()) )
Y = Y.ravel()
Ytest = Ytest.ravel()
# --- Layers
# ----------------------
HL = []
HL.append( hosgdHLFunDense(nShp=512, actFun=actFun) )
HL.append( hosgdHLFunSoftMax(nShp=10) )
# --- Optimization model
# ----------------------
OptProb = hosgdHLOptProb(X, Y, 10, HL, verbose=verbose, Xtest=Xtest, Ytest=Ytest)
# --- HyperPar (this is kept in order to have a similar structure to the SD case (see Lab 1a)
# ------------
hyperP = hosgdHyperFunSGD(lrPolicy=lrPolicy, lrSDecay=lrSDecay, lrTau=lrTau)
# --- Select SGD sgdVariant
# ----------------------
if isinstance(alpha,float):
sgdVar = hosgdBBSGD(alpha, hyperP)
mtmVar = hosgdBBSGDmtm(alpha, hyperP,gamma=0.9)
else:
sgdVar = hosgdBBSGD(alpha[0], hyperP)
mtmVar = hosgdBBSGDmtm(alpha[1], hyperP,gamma=0.9)
# --- Call GD
# -----------
W = []
stats = []
nameVar = []
# SGD
sol = hosgdSGDHLSover(OptProb, sgdVar, nEpoch, blkSize)
W.append(sol[0])
stats.append(sol[1])
nameVar.append('SGD')
# Momentum
sol = hosgdSGDHLSover(OptProb, mtmVar, nEpoch, blkSize)
W.append(sol[0])
stats.append(sol[1])
nameVar.append('SGD-MTM')
# --- Plot results
# ----------------
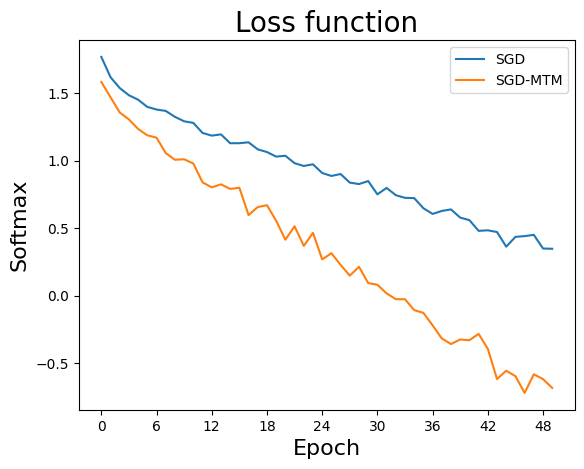
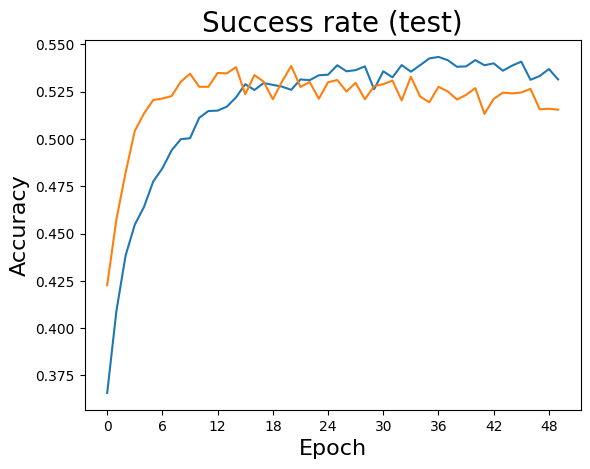
plotSGDStatsList(stats, nameVar)
return W, stats
Simple Simulation (CIFAR-10)
import numpy as np
import HoSGDdefs as hosgdDef
import HoSGDlabHL as HL
sol = HL.exHLMultiClass(50, 128, np.array([0.001,0.00025]), dataset='cifar10', verbose=10, actFun=hosgdDef.actFun.ReLU)